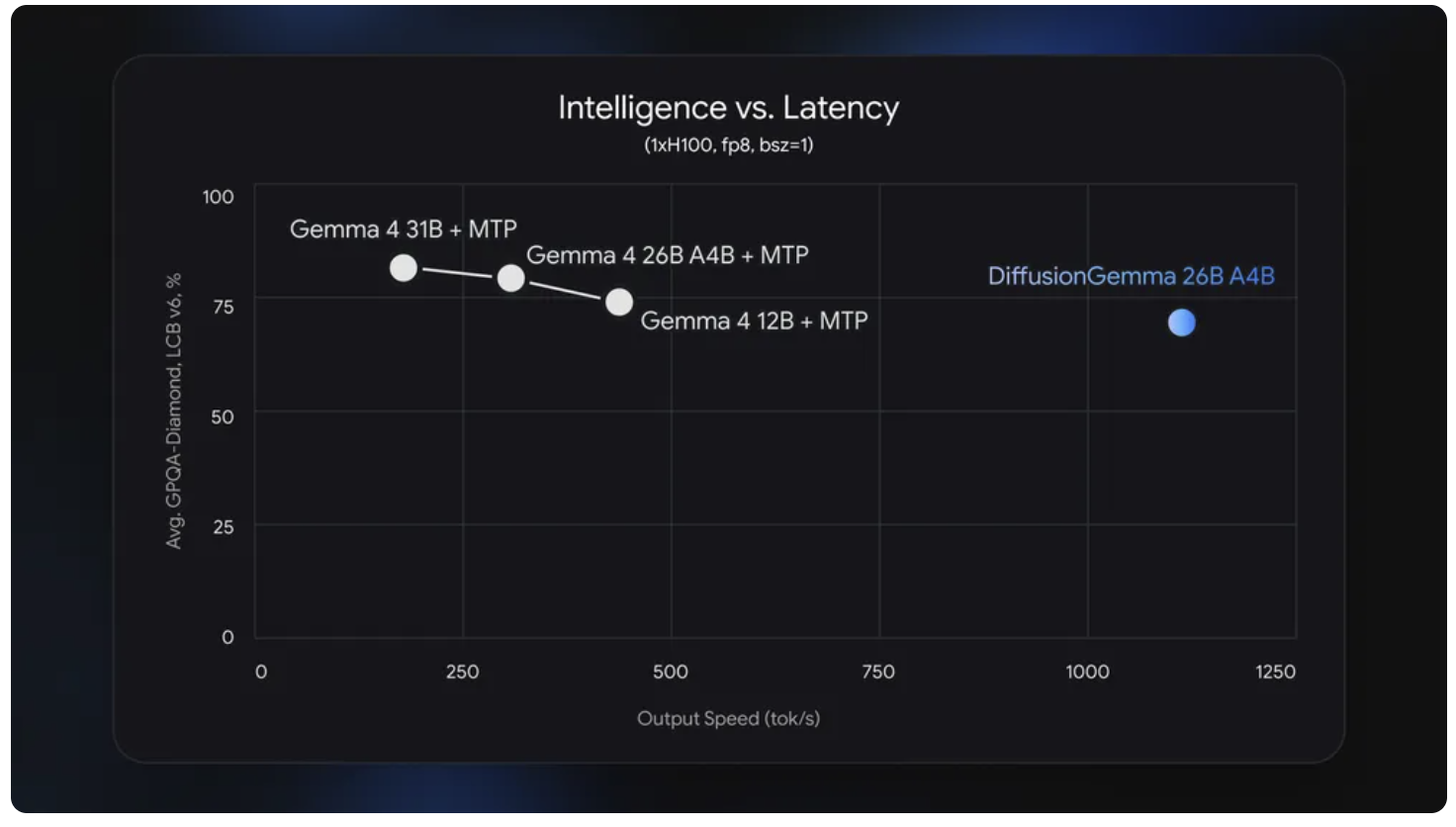
谷歌今天发布了DiffusionGemma ,这是一个开放模型人工智能,生成文本的方式类似于图像生成器生成图片:从噪声开始,逐步优化,直到产生有意义的内容。它在NVIDIA H100上每秒处理1,000个标记。(标记是AI模型处理的信息基本单位。)这意味着它比普通Gemma快四倍。同时,它是免费的,使用Apache 2.0许可,权重在Hugging Face上可用。
而总是要提到的一个陷阱在于小字。根据谷歌的公告,该模型在“NVIDIA GeForce RTX 5090上每秒可以处理700多个标记。”而且它在输出质量上逊色于标准Gemma 4。
谷歌自己也这么说。这是一个速度模型,而不是质量升级。
它实际做了什么
你使用的每个LLM都是一种打字机。一个一个标记地生成,每个词都依赖于上一个。这就是自回归架构的工作方式。
但是DiffusionGemma不是这样。它不是按顺序生成标记,而是从精细化的混乱文本块开始并行生成。根据谷歌的开发者指南,它“从随机占位符标记的画布开始”,并逐步锁定自信的标记,直到整个块清晰聚焦。每次前向传递256个标记。GPU保持繁忙。

副作用是双向注意力——每个标记在生成时可以看到每个其他标记,这在自回归模型中是不可能的(它们无法看到未来,要编码的内容)。这使得它在那些答案末尾约束开头的任务中表现得尤为出色:代码填充、结构化输出、约束重的问题等等。谷歌对一个版本进行了微调,以解决数独作为演示。基础模型大约正确地解决了0%的难题。
微调版本达到80%。
文本扩散已经是一个研究项目多年。MDLM、SEDD、LLaDA、Dream——这些学术模型证明了该方法在小规模上有效,主要停留在概念验证阶段。Inception Labs在2026年2月发布了Mercury 2,这是第一个商业扩散推理模型,声称速度是速度优化竞争对手的五倍。
但这些都不是开放权重,并且没有在vLLM、Hugging Face Transformers和Unsloth中提供零日支持。DiffusionGemma是第一款来自顶级实验室的大型开放发布。
还有一个值得注意的历史讽刺。图像生成器最初作为扩散模型(因此名为稳定扩散)开始,现在正朝着自回归架构发展以提高质量。语言模型最初是自回归的,现在正通过扩散进行速度实验。
为什么现在运行起来很麻烦
高效运行DiffusionGemma需要一个起草者——一个轻量级模块,以并行方式提议标记块,主模型则在一次前向传递中验证。这被称为推测解码。DFlash是一个在2026年初发布的框架,使用一个小的扩散模型作为起草者,在某些任务上实现了超过6倍的加速。这是使这一类模型实用的引擎。
问题是:DiffusionGemma需要特定的起草者才能通过MLX在本地运行——苹果为苹果硅设计的机器学习框架。这个模块在任何公共版本的mlx-lm、任何开放的拉取请求或LM Studio的捆绑运行时中都不存在。
我们尝试通过NVIDIA NIM使用Hermes运行DiffusionGemma。模型加载了,但随后却出现:“代理初始化失败:模型google/diffusiongemma-26b-a4b-it的上下文窗口为8192个标记,这低于Hermes Agent所需的最小64000。”
准确地说:DiffusionGemma的实际上下文窗口是256K标记。8192的数字是Nvidia默认的错误设置,而不是模型的架构限制。
实际上,正确配置它以用于代理使用需要手动工作,大多数普通用户尚未弄明白,而Hermes Agent根本无法初始化。并行速度毫无意义,如果代理无法启动。
希望在接下来的几天里,社区能够提供更好的资源来运行这些模型。
这实际上适合谁
拥有NVIDIA RTX 4090或5090硬件的开发者,构建实时工具——内联编辑器、自动完成、代码填充、结构化生成。这是目标。正如Decrypt在五月报道的那样,谷歌一直在稳步推进,使本地推断速度更快,而无需新的硬件。
对于研究人员,双向生成打开了自回归模型根本无法达到的领域——蛋白质序列、数学图、任何位置N依赖于位置N+50的内容。这不是一件小事。
谷歌在四月份以Apache 2.0协议发布了Gemma 4,而DiffusionGemma继续这一战略。截至今天,已经有一个草稿的llama.cpp PR打开。随着工具链的跟进,这将吸引更广泛的受众。
在一台配备强大独立GPU的机器上,每秒处理1,000个标记是真实的。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





