If you've been following the local AI scene, you probably know Qwopus—the open-source model that tried to distill Claude Opus 4.6's reasoning into Alibaba's Qwen, so you could run something resembling Opus on your own hardware for free. It worked surprisingly well. The obvious catch: Qwen is a Chinese model, and not everyone is comfortable with that.
Jackrong, the same pseudonymous developer behind that project, heard the feedback. His answer is Gemopus—a new family of Claude Opus-style fine-tunes built entirely on Google's open-source Gemma 4. All-American DNA, same idea: frontier-level reasoning, running locally on hardware you already own.
The family comes in two flavors. Gemopus-4-26B-A4B is the heavier option—a Mixture of Experts model that has 26 billion total parameters but only activates around 4 billion during inference, which means it punches well above its weight on constrained hardware.
Parameters are what determine an AI's capacity to learn, reason, and store information. Having 26 billion total parameters gives the model a huge breadth of knowledge. But by only "waking up" the 4 billion parameters relevant to your specific prompt, it delivers the high-quality results of a massive AI while remaining lightweight enough to run smoothly on everyday hardware.
The other is Gemopus-4-E4B, a 4-billion parameter edge model engineered to run comfortably on a modern iPhone or a thin-and-light MacBook—no GPU required.
The base model choice matters here. Google's Gemma 4, released on April 2, is built directly from the same research and technology as Gemini 3—the company said so explicitly at launch. That means Gemopus carries something no Qwen-based fine-tune can claim: The DNA of Google's own state-of-the-art closed model under the hood, wrapped in Anthropic's thinking style on top. The best of both worlds, more or less.
What makes Gemopus different from the wave of other Gemma fine-tunes flooding Hugging Face right now is the philosophy behind it. Jackrong deliberately chose not to force Claude's chain-of-thought reasoning traces into Gemma's weights—a shortcut most competing releases take.
His argument, backed by recent research, is that stuffing a student model with a teacher's surface-level reasoning text doesn't actually transfer real reasoning ability. It teaches imitation, not logic. "There is no need for excessive imagination or superstitious replication of the Claude-style chain of thought," the model card reads. Instead, he focused on answer quality, structural clarity, and conversational naturalness—fixing Gemma's stiff Wikipedia tone and its tendency to lecture you about things you didn't ask.
AI infrastructure engineer Kyle Hessling ran independent benchmarks and published the results directly on the model card. His verdict on the 26B variant was pretty favorable. "Happy to have benched this one pretty hard and it is an excellent finetune of an already exceptional model,” he wrote on X. “It rocks at one-shot requests over long contexts, and runs incredibly fast thanks to the MOE (mixture of experts) architecture."
The smaller E4B variant passed all 14 core competence tests—instruction following, coding, math, multi-step reasoning, translation, safety, caching—and cleared all 12 long-context tests at 30K and 60K tokens. On needle-in-haystack retrieval, it passed 13 out of 13 probes including a stretch test at one million tokens with YaRN 8× RoPE scaling.
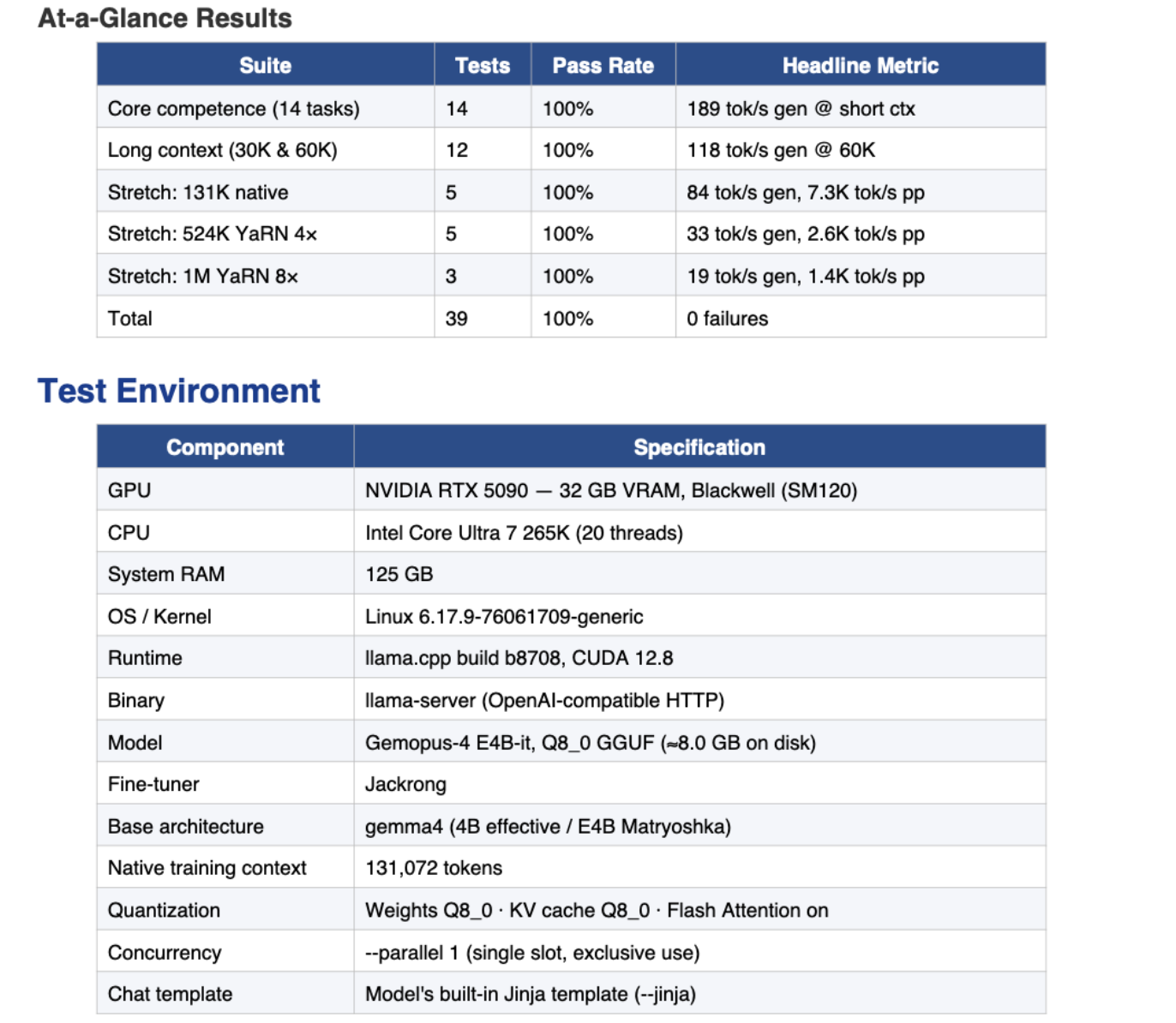
The 26B extends natively to 131K context and all the way out to 524K with YaRN, which Hessling also stress-tested: "It also crushed my simple needle-in-the-haystack tests all the way out to an extended context of 524k!"
On edge hardware, the E4B is genuinely fast. Jackrong reports 45–60 tokens per second on iPhone 17 Pro Max, and 90–120 tokens per second on MacBook Air M3/M4 via MLX. The 26B MoE architecture means it offloads gracefully on unified memory systems or GPUs with under 10GB of VRAM. Hessling called it his daily driver recommendation for VRAM-starved setups.
Both models are available in GGUF format, which means you can drop them straight into LM Studio or llama.cpp without configuration. The full training code and a step-by-step fine-tuning guide are on Jackrong's GitHub—same pipeline he used for Qwopus, same Unsloth and LoRA setup, reproducible on Colab.
Gemopus is not without its rough edges. Tool calling remains broken across the entire Gemma 4 series in llama.cpp and LM Studio—call failures, format mismatches, loops—so if your workflow depends on agents using external tools, this is not your model yet. Jackrong himself calls it "an engineering exploration reference rather than a fully production-ready solution," and recommends his own Qwopus 3.5 series for anyone who needs something more stable for real workloads.
And because Jackrong deliberately avoided aggressive Claude-style chain-of-thought distillation, don't expect it to feel as deeply Opus-brained as Qwopus—that was a conscious tradeoff for stability, not an oversight.
For those who want to go deeper into Gemma fine-tuning for reasoning specifically, there is also a separate community project worth watching: Ornstein by pseudonmyous developer DJLougen, which takes the same 26B Gemma 4 base and focuses specifically on improving its reasoning chains without relying on the logic or style of any specific third party model.
One honest caveat: Gemma's training dynamics are messier than Qwen's for fine-tuners—wider loss fluctuations, more hyperparameter sensitivity. Jackrong says so himself. If you need a more battle-tested local model for production workflows, his Qwopus 3.5 series remains more robustly validated. But if you want an American model with Opus-style polish, Gemopus is currently your best available option. A denser 31B Gemopus variant is also in the pipeline, with Hessling teasing it as "a banger for sure."
If you want to try running local models on your own hardware, check our guide on how to get started with local AI.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






