在自己的计算机上运行人工智能模型是很棒的——直到它变得不那么棒。
承诺是隐私、无需订阅费用,数据不会离开你的机器。对大多数人来说,现实是看到光标在句子之间闪烁五秒钟。
这个瓶颈有一个名字:推理速度。它与模型的智能程度无关。这是一个硬件问题。标准的人工智能模型一次生成一个单词片段——称为一个令牌。硬件必须把数十亿个参数从内存传送到计算单元,仅仅是为了生成每一个令牌。设计上就是慢的。在消费级硬件上,这种速度是让人痛苦的。
大多数人通常采用的解决方法是运行更小、更弱的模型——或者 heavily compressed versions,称为量化模型,为了速度牺牲一些质量。这两种解决方案都不好。你可以得到某种可以运行的东西,但它并不是你真正想要的模型。
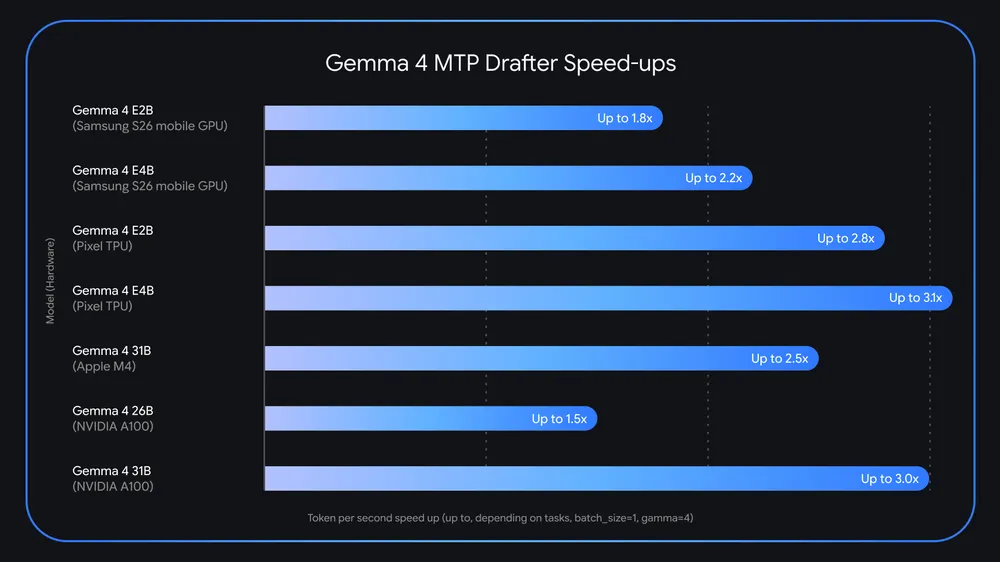
现在谷歌有了不同的想法。该公司刚刚为其Gemma 4系列开放模型发布了多令牌预测(MTP)起草器——一种可以在不触及模型质量或推理能力的情况下提供高达3倍速度提升的技术。
这种方法被称为投机解码,作为一个概念已经存在多年。谷歌的研究人员在2022年发表了基础论文。这个想法直到现在才变得主流,因为它需要正确的架构在规模上发挥作用。
下面是它如何运作的简短版本。与其让强大的大模型单独承担所有工作,不如将其与一个小型“起草器”模型配对。这个起草器既快速又廉价——它同时预测几个令牌所需的时间比大模型生成一个令牌还要短。然后大模型在一次传递中检查所有这些猜测。如果猜测正确,那么你将以一次前向传递的价格获得整个序列。
据谷歌称,“如果目标模型同意草稿,它将在一次前向传递中接受整个序列——并在这个过程中甚至生成一个额外的令牌。”
没有任何牺牲:大型模型——例如Gemma 4的31B密集版本——仍然验证每一个令牌,输出质量完全相同。你只是在利用在慢速部分闲置的计算能力。
谷歌表示,起草器模型共享目标模型的KV缓存——一种存储已经处理的上下文的内存结构——因此它们不会浪费时间重新计算更大模型已经知道的事情。针对手机和树莓派设备设计的小型边缘模型,团队甚至构建了一种高效的聚类技术,以进一步缩短生成时间。
这并不是人工智能领域尝试并行生成文本的唯一尝试。基于扩散的语言模型——如来自Inception Labs的Mercury——采用了完全不同的方法:它们不是一次预测一个令牌,而是从噪音开始,并逐步细化整个输出。这在纸面上是快的,但扩散LLM在匹配传统变压器模型的质量方面苦苦挣扎,使它们更像是研究的好奇而非实用工具。
投机解码不同之处在于,它根本不改变基础模型。这是一种服务优化,而不是架构替代。你已经运行的同一个Gemma 4变得更快。
实际的好处是显而易见的。根据谷歌自己的基准测试,一个在Nvidia RTX Pro 6000桌面GPU上运行的Gemma 4 26B模型在启用MTP起草器的情况下每秒大约可以处理两倍的令牌。在Apple硅处理器上,4到8个请求的批量大小能够解锁大约2.2倍的速度提升。虽然在每种情况下未达到3倍的上限,但在“几乎无法使用”和“实际上足够快以便工作”之间仍然有明显的差异。
这里上下文很重要。当中国模型DeepSeek在2025年1月震惊市场——在短短一天内抹去6000亿美元的Nvidia市值——主要教训是,效率提升可以比单纯计算能力的提升影响更大。更智能的运行胜过向问题投入更多硬件。谷歌的MTP起草器是朝这个方向迈出的又一步,但其目标明确指向消费市场的末端。
整个人工智能行业目前是一个考虑推理、训练和内存的三角形。每个领域的突破往往会推动或震惊整个生态系统。DeepSeek的训练方法(使用低端硬件实现强大模型)是一个例子,而谷歌的TurboQuant(在不失去质量的情况下缩小AI内存)论文则是另一个。两者都使市场崩溃,因为公司试图弄清楚该如何应对。
谷歌表示,起草器可以解锁“改进的响应能力:大幅降低近实时聊天、沉浸式语音应用程序和代理工作流的延迟”——这类任务需要低延迟才能感到实用。
使用案例很快就能清晰可见:一个没有延迟的本地编码助手;一个在你还未忘记所问问题之前就做出响应的语音接口;一个在步骤之间不让你等待三秒钟的代理工作流。这一切,都在你已有的硬件上。
MTP起草器现在可以在Hugging Face、Kaggle和Ollama上获得,遵循Apache 2.0许可证。它们与vLLM、MLX、SGLang和Hugging Face Transformers即插即用。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







