A few days ago, Stella Laurenzo, head of the AMD AI team, released an issue report titled "Claude Code is no longer usable for complex engineering tasks" in the official Claude Code repository. This is not an emotional complaint from a user, but a quantitative analysis based on 6,800 conversations. It lays out the most uncomfortable problems for the AI community, highlighted by a particularly glaring set of figures: configurations made by Anthropic to save computing power burned this team's API monthly bill from $345 to $42,121.
Laurenzo's team tracked 235,000 tool calls and 18,000 prompts, recording a systematic degradation of abilities in Claude Code that began in February 2026. This report was later covered by The Register, sparking a public outcry in the developer community that lasted two weeks.
Boris Cherny, head of the Anthropic Claude Code team, provided an explanation on Hacker News. With the release of Opus 4.6 on February 9, a default "adaptive thinking" mechanism was enabled, allowing the model to autonomously decide how long to think. On March 3, Anthropic reduced the default thinking intensity to 85. The official explanation is "the best balance point between intelligence, latency, and cost." The actual effects of these two adjustments are evident from the data.
Thinking Depth Decreased by Three Quarters
According to Stella Laurenzo's GitHub Issue data, Claude Code's average thinking depth experienced a three-stage collapse over two months: from 2,200 characters at the end of January, it dropped to 720 characters by the end of February, a decrease of 67%. It further shrank to 560 characters in March, a 75% drop from its peak.
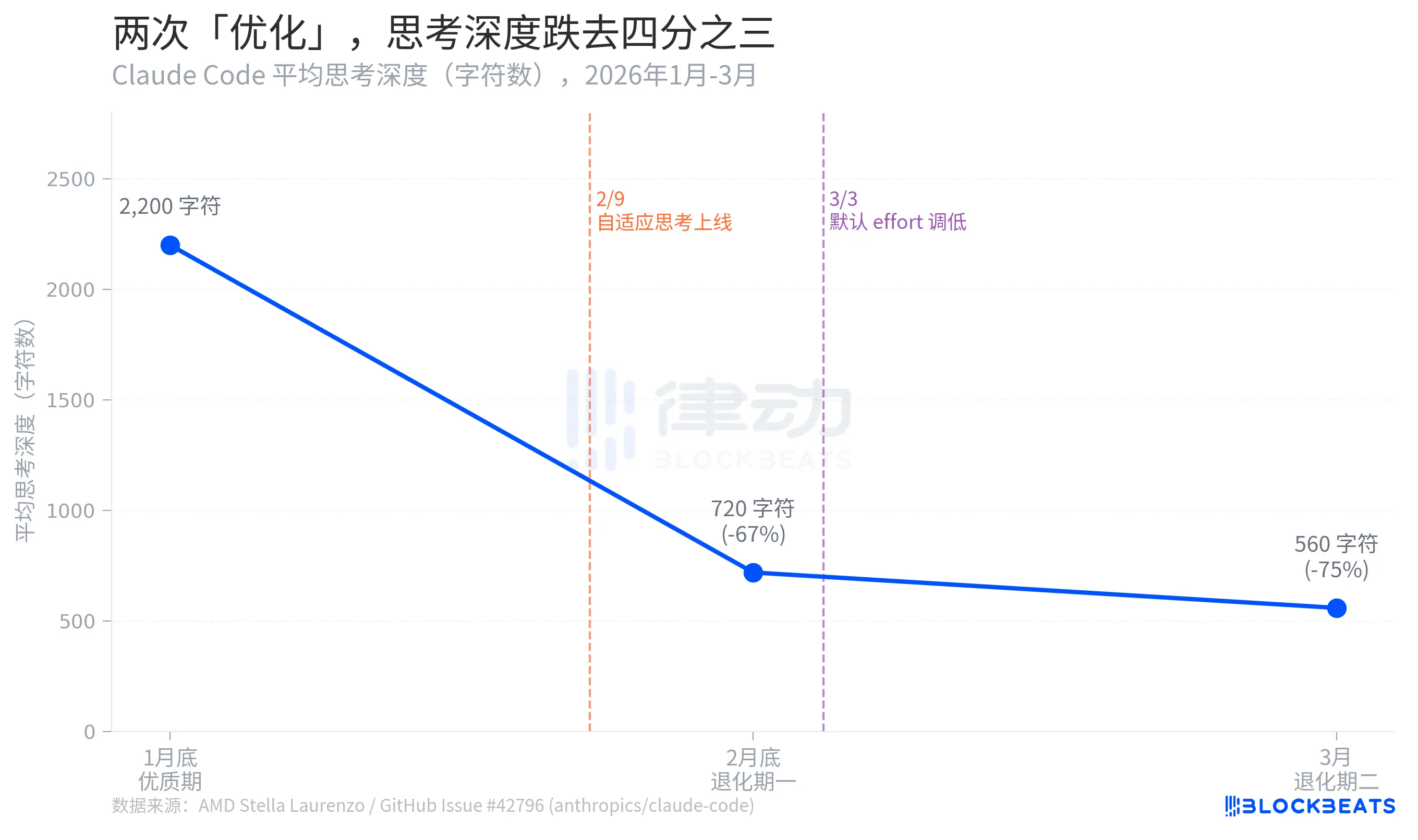
Here, thinking depth serves as a proxy indicator reflecting how much "internal reasoning" the model is willing to invest before giving an answer. The difference between 2,200 characters and 560 characters roughly equates to a regression from "writing a draft before answering" to "thinking for two seconds before speaking."
Laurenzo also pointed out that the "redact thinking" feature (redact-thinking-2026-02-12) launched in early March obscured the model's thinking process during this period, preventing users from intuitively perceiving the shrinkage. Boris Cherny insisted this was merely a user interface change that did not affect the underlying reasoning. Both claims are technically valid, but from the user perspective, the effect is indistinguishable.
Boris Cherny later admitted that even if the effort is manually set back to the highest level, the adaptive thinking mechanism may still allocate insufficient reasoning in certain rounds and may produce hallucinated content. "Restoring maximum effort" is not a complete solution; it merely adjusts the dial back to a position close to the original rather than restoring the original certainty.
From "Research Programmer" to "Blind Modifier"
A detail in Stella Laurenzo's report is more straightforward than thinking depth: how many relevant files the model actively reads before changing code.
According to GitHub Issue data, the average read-modify ratio during the quality period was 6.6. Before modifying a piece of code, the model averaged reading 6.6 files to understand the context. During the degradation period, this number dropped to 2.0, a decrease of 70%. More worryingly, about one-third of code changes occurred without the model reading the target files first, leading to direct modifications.
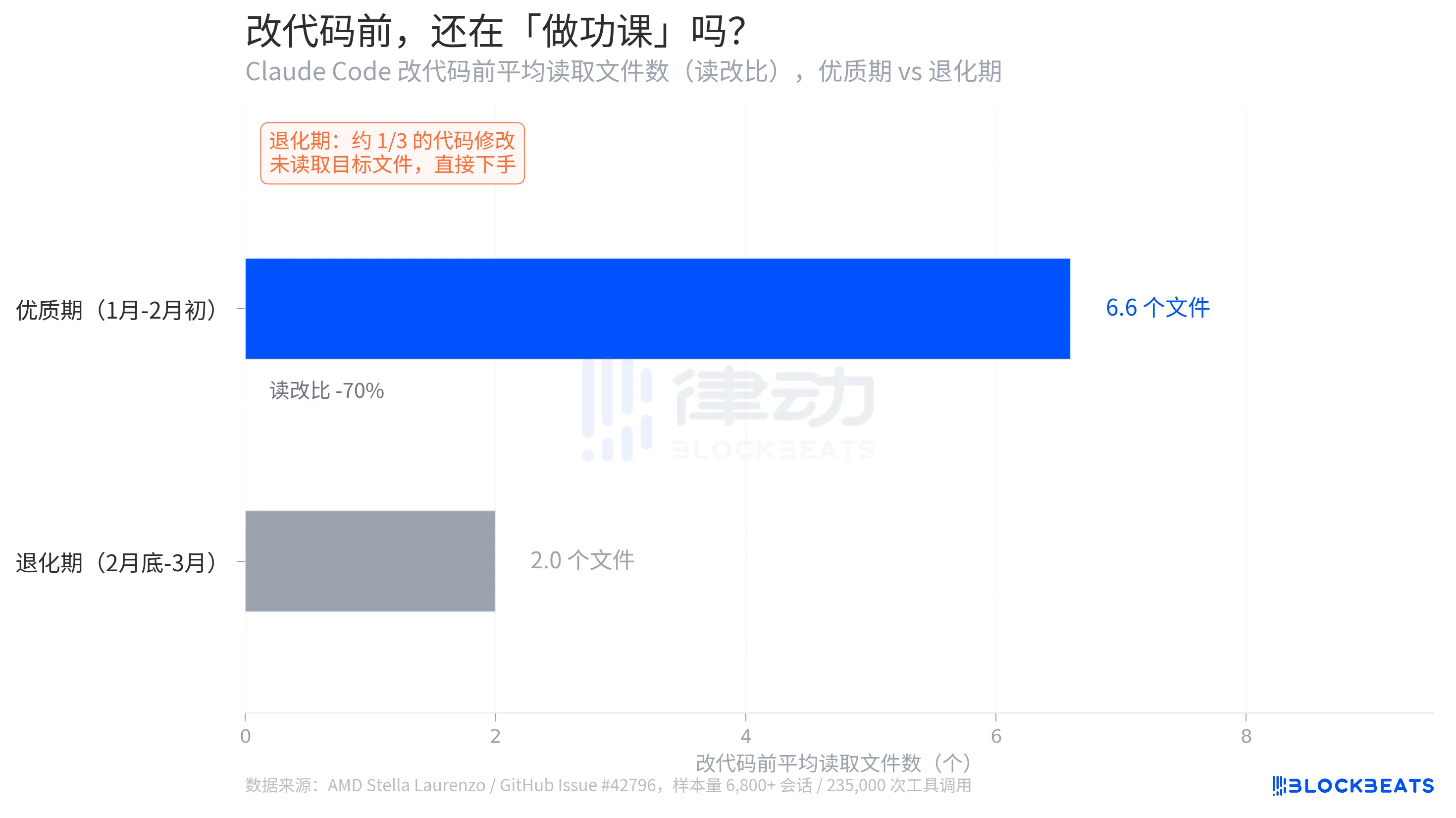
Laurenzo referred to this as "blind edits." In engineering terms, this is akin to a programmer starting to write code without looking at the function signatures or knowing the variable types. "Every senior engineer on my team has had similar personal experiences," she wrote in the report. "Claude can no longer be trusted to carry out complex engineering tasks."
The drop in the read-modify ratio from 6.6 to 2.0 superficially indicates a change in behavior metrics but fundamentally reflects a collapse in task success rates. The complexity of modern codebases means any modifications involve dependencies among multiple files. Skipping context exploration for direct modifications leads to errors not just being "incorrect," but "appearing correct yet triggering new errors downstream. The cost of troubleshooting such errors is far higher than that of a single clear failure."
The Miscalculation of "Saving Money"
This is the most counterintuitive set of figures in the entire incident, coming from the same GitHub Issue data: Stella Laurenzo's team saw the monthly calling cost for the Claude Code API soar from $345 in February 2026 to $42,121 in March, a 122-fold increase.
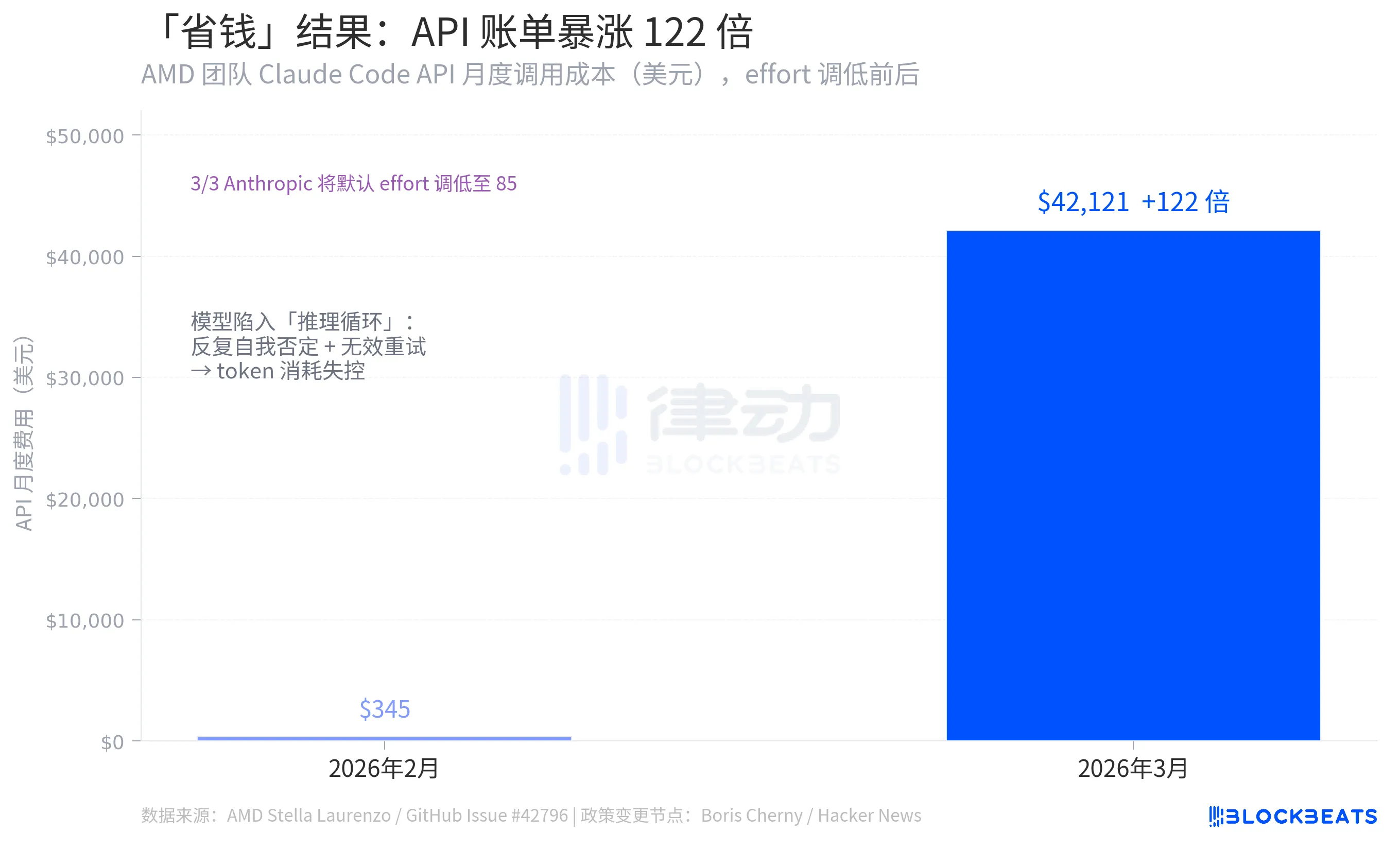
Ananthropic's logic for lowering effort was to reduce the token consumption per call and thus lower costs. However, the opposite effect was observed. The reason lies in the emergence of numerous "reasoning loops" after model degradation, where the model repeatedly self-negates within a single response, leading to excessive token consumption far exceeding the intended savings. According to Stella Laurenzo's data, the rate at which users actively interrupted tasks soared 12-fold during this period, necessitating continuous developer intervention, correction, and resubmission.
The underlying logic reveals a systemic error. Cutting computing power on complex tasks does not equivalently lower costs. Once below a certain thinking threshold, the model begins to take detours, amplifying total costs instead. Reducing effort saves money on simple queries, but it blew up the bills on coding engineering tasks.
The "Dumbing Down" Issue, Replayed by GPT-4 Three Years Ago
In July 2023, research teams from Stanford University and the University of California, Berkeley published a paper on arXiv titled "How is ChatGPT's behavior changing over time?" documenting a similar process that occurred with GPT-4.
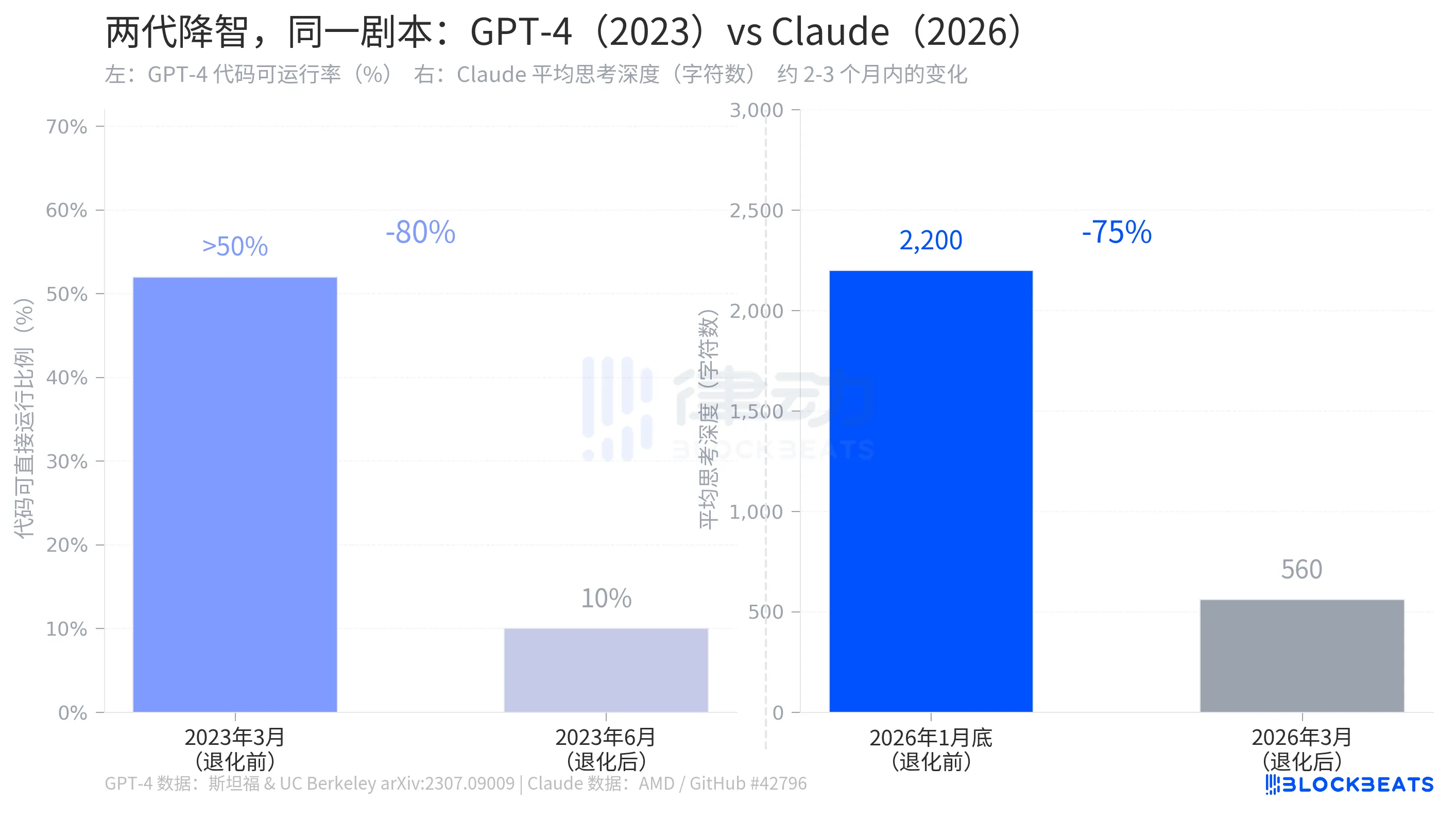
According to the study’s data, for GPT-4 in March 2023, over 50% of the generated code was directly runnable. By June, that ratio plummeted to 10%, a drop of approximately 80%, over a span of three months. During the same period, the accuracy of prime number detection fell from 97.6% to 2.4%. OpenAI's response was highly similar to Anthropic's: there had been optimizations in the background, which were part of normal iterations.
The structure of the two stories is almost identical: an AI company quietly adjusted parameters affecting model capabilities in the background, users sensed the changes, and the company acknowledged the adjustments, explaining them as "more reasonable resource allocation." The degradation of GPT-4 occurred in 2023, while Claude's degradation occurred in 2026, three years apart with the same script.
This is not a unique error of any one company. The economic logic behind AI subscription models dictates that when the cost of reasoning exceeds the range that pricing can cover, manufacturers face the same pressure. Lowering the default thinking intensity is currently the easiest knob to turn between cost and performance. What users perceive is that the model has "become dumber." What manufacturers show as savings is the marginal token cost per call.
Boris Cherny offered a technical solution: users can restore thinking intensity to the highest level by manually executing the /effort high command or modifying configuration files. This solution is technically feasible, but it also means that "highest performance" is no longer the default setting.
The jump from $345 to $42,121 wasn't just a budget blow; it dismantled an assumption: that the default configuration changes made by manufacturers were to ensure a better user experience.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






