几天前,AMD AI 团队负责人 Stella Laurenzo 在 Claude Code 官方仓库发布了一份标题为「Claude Code 对复杂工程任务已无法使用」的问题报告。这不是一条用户情绪化的投诉,而是一份基于 6,800 个会话的定量分析。它把 AI 圈最不愿面对的问题摆上了桌面,其中有一组数字尤其刺眼:Anthropic 为省算力做的配置调整,把这个团队的 API 月度账单从 345 美元烧到了 42,121 美元。
Laurenzo 的团队追踪了 235,000 次工具调用、18,000 条提示词,记录了 Claude Code 从 2026 年 2 月起出现的系统性能力退化。这份报告随后被 The Register 报道,在开发者社区引发了持续两周的舆论风暴。
Anthropic Claude Code 团队负责人 Boris Cherny 在 Hacker News 作出了说明。2 月 9 日随 Opus 4.6 发布时,默认启用了由模型自主决定思考时长的「自适应思考」机制。3 月 3 日,Anthropic 又把默认思考强度(effort)调低至 85。官方的解释是「在智能、延迟与成本之间的最佳平衡点」。这两次调整的实际效果,数据说得很清楚。
思考深度,跌了四分之三
据 Stella Laurenzo 的 GitHub Issue 数据,Claude Code 的平均思考深度在两个月内经历了三段式崩塌:1 月底优质期的 2,200 字符,到 2 月底跌至 720 字符,跌幅 67%。3 月进一步萎缩至 560 字符,较峰值跌去 75%。
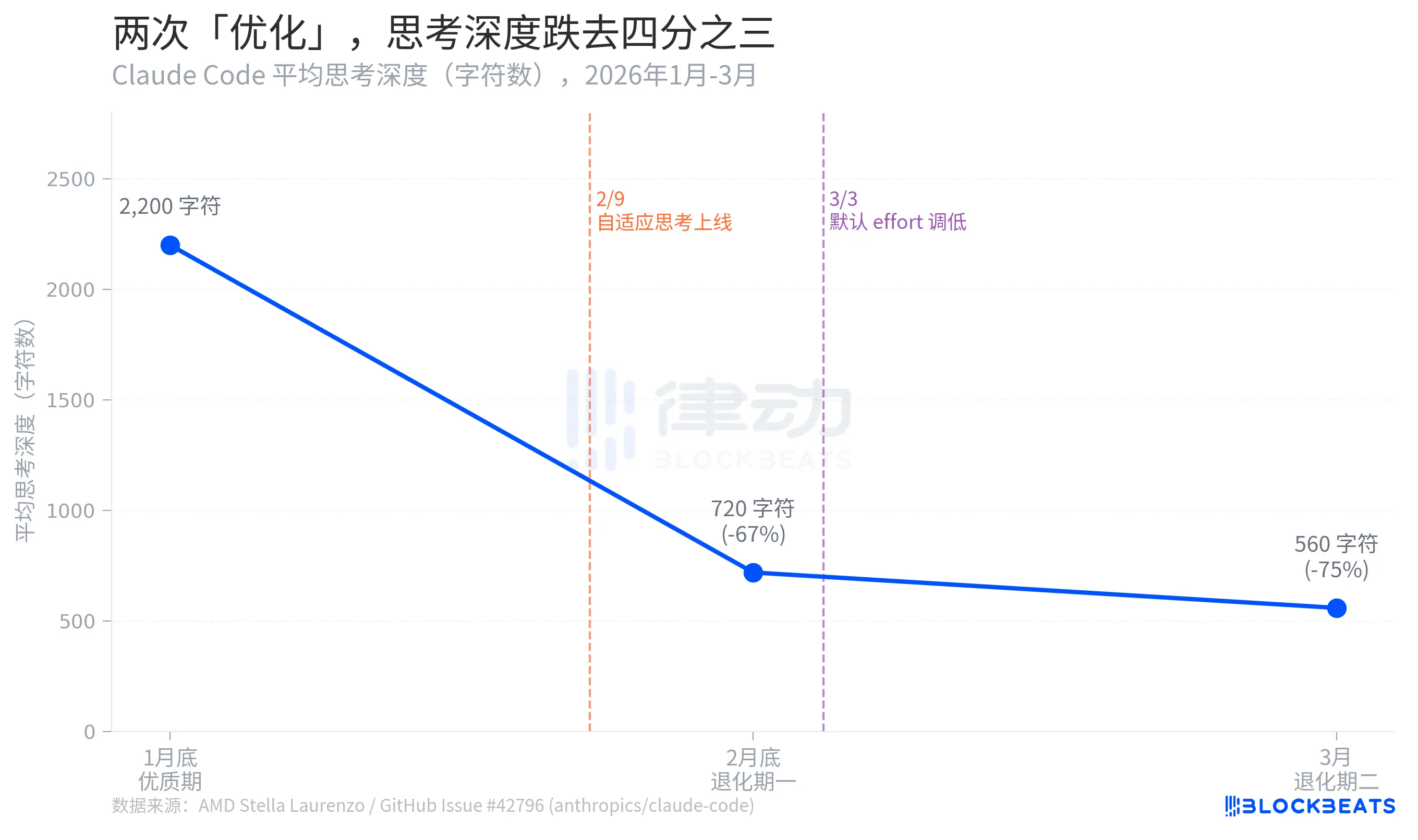
思考深度在这里是个代理指标,反映模型在给出答案前愿意投入多少「内部推演」。2,200 字符和 560 字符的差距,大致等同于从「写完草稿再作答」退化为「脑子里想两秒就开口」。
Laurenzo 还指出,3 月初上线的「思考内容隐藏」功能(redact-thinking-2026-02-12)恰好在这段时间遮蔽了模型思考过程,让用户无法直观感知缩水。Boris Cherny 坚持这只是界面改动,不影响底层推理。两种说法在技术上都成立,但从用户侧来看,效果上没有区别。
Boris Cherny 后来也承认,即使手动将 effort 设回最高,自适应思考机制仍可能在某些轮次分配推理不足,并可能产生幻觉内容。「恢复最高 effort」并不是一个完整的解法,它只是把旋钮拨回了靠近原来的位置,而不是恢复到原有的确定性。
从「研究型程序员」到「盲改型程序员」
Stella Laurenzo 的报告里有个细节比思考深度更直白:改代码前,模型会主动读多少个相关文件。
据 GitHub Issue 数据,优质期的平均读改比是 6.6,改动一处代码前,模型平均会先读 6.6 个文件,了解上下文。退化期这个数字跌到 2.0,降幅 70%。更严重的是,约三分之一的代码修改发生在模型未读取目标文件的情况下,直接下手。
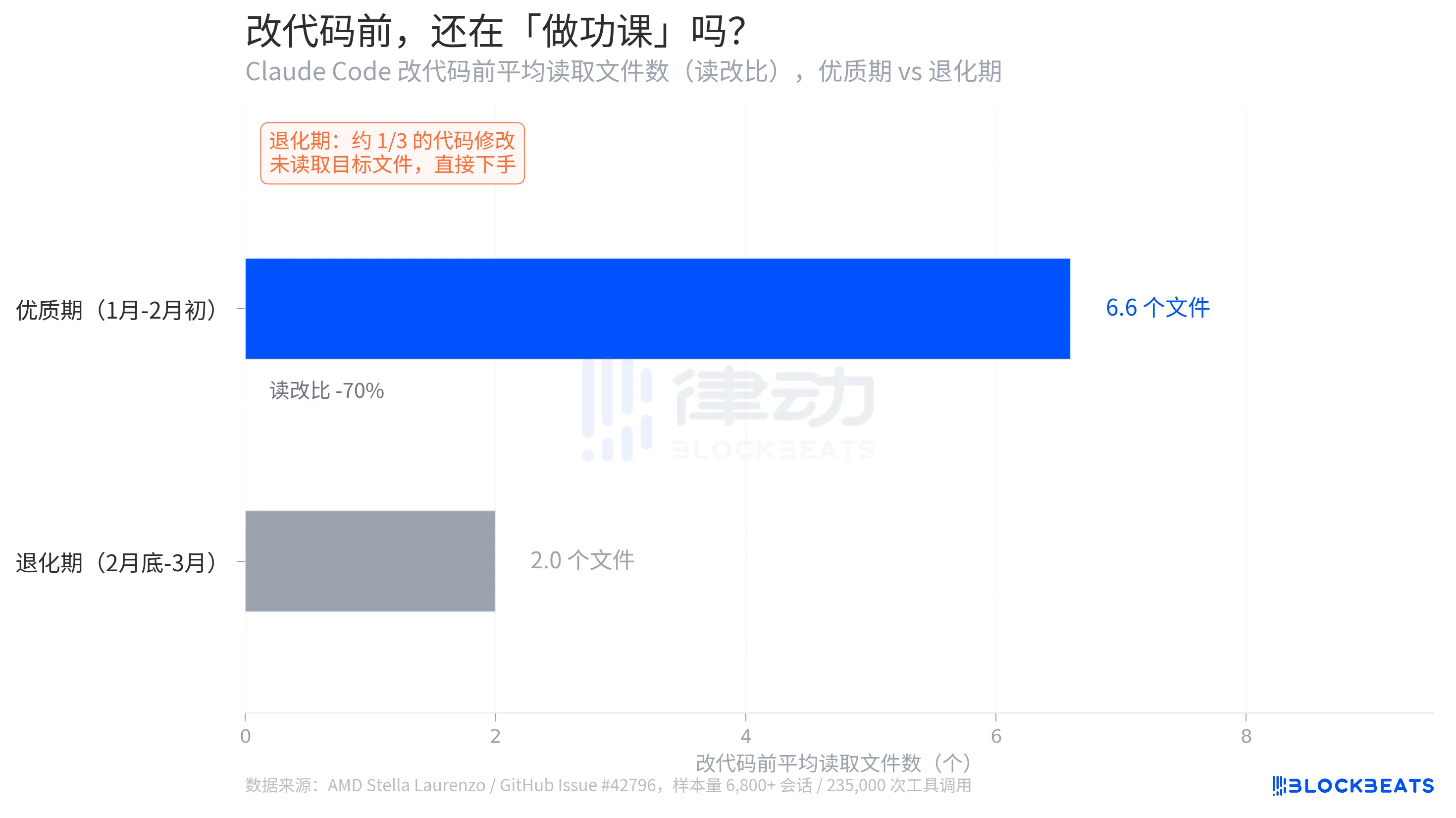
Laurenzo 称之为「盲改」(blind edits)。工程上,这相当于一个程序员在不看函数签名、不知道变量类型的情况下就开始写代码。「我团队的每一位高级工程师都有类似的亲身遭遇。」她在报告中写道,「Claude 现在不能被信赖去执行复杂的工程任务。」
读改比从 6.6 到 2.0,表面是一个行为指标的变化,底层是任务成功率的塌陷。现代代码库的复杂度决定了,任何修改都牵涉多个文件之间的依赖关系。跳过上下文探索直接修改,产生的错误不是「答错了」,而是「看起来对,但会在下游触发新的错误。这类错误的排查成本,远高于一次失败的明确回答。
「省钱」这件事,算反了
这是整个事件里最反直觉的一组数字,来自同一份 GitHub Issue 数据:Stella Laurenzo 团队的 Claude Code API 月度调用成本,从 2026 年 2 月的 345 美元,到 3 月飙升至 42,121 美元,涨幅 122 倍。
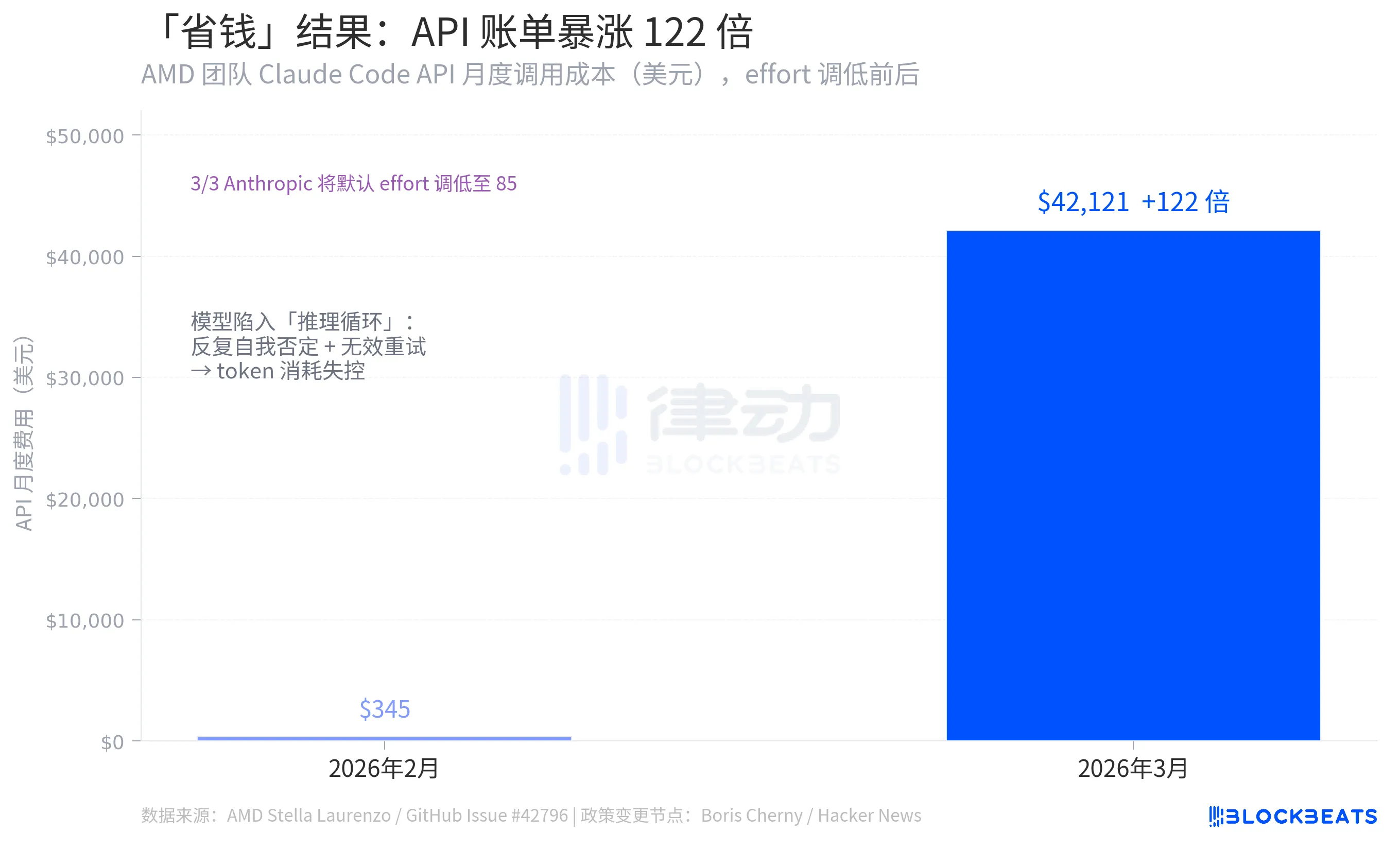
Anthropic 调低 effort 的逻辑是减少单次调用的 token 消耗,从而降低成本。但结果相反。原因在于模型退化后出现了大量「推理循环」(Reasoning Loops),在单次回复中反复自我否定,不断重来,用掉的 token 远超节省的量。据 Stella Laurenzo 的数据,同期用户主动中断任务的比率飙升了 12 倍,开发者需要不停介入、纠错、重新提交。
背后的逻辑是一个系统性错误。在复杂任务上砍算力,并不会简单地等比降低成本。一旦低于某个思考阈值,模型开始走弯路,总成本反而放大。调低 effort 在简单查询上省了钱,在代码工程任务上,它把账单炸了。
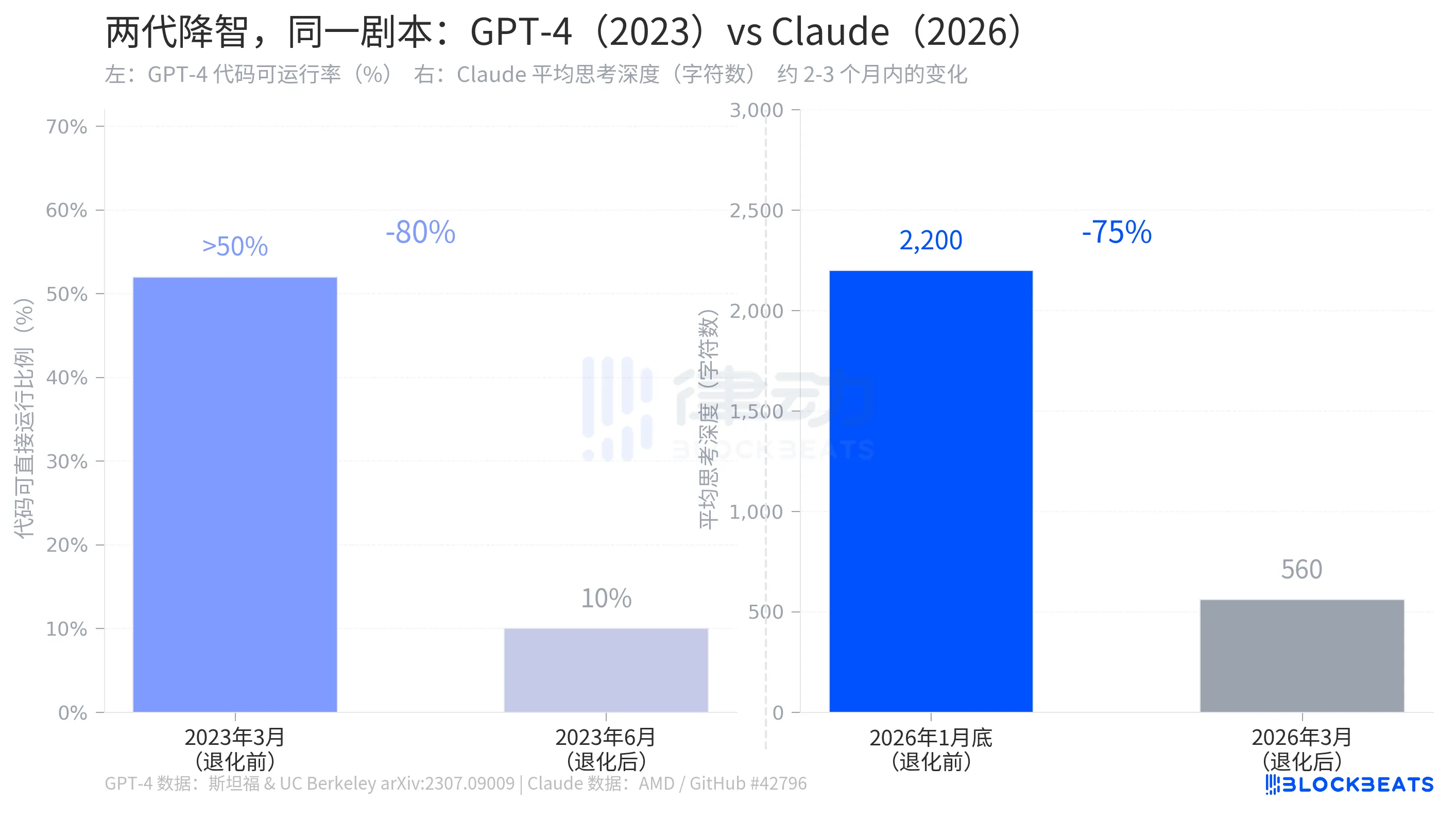
「降智」这事,GPT-4 三年前演过一遍
2023 年 7 月,斯坦福大学与加州大学伯克利分校的研究团队在 arXiv 发表论文《How is ChatGPT's behavior changing over time?》,记录了同一件事在 GPT-4 上的发生过程。
据该研究数据,2023 年 3 月的 GPT-4,生成的代码中超过 50% 可以直接运行。到 6 月,这个比例跌至 10%,跌幅约 80%,时间跨度三个月。同期,素数识别准确率从 97.6% 跌至 2.4%。OpenAI 的回应和 Anthropic 高度相似:后台有过优化调整,属于正常迭代。
两个故事的结构几乎一致,一家 AI 公司在后台悄悄调整了影响模型能力的参数,用户察觉到了,公司承认有过调整,但把原因解释为「更合理的资源分配」。GPT-4 的退化发生在 2023 年,Claude 的退化发生在 2026 年,两者相隔三年,剧本一样。
这不是某家公司的特殊失误。AI 订阅模式的经济逻辑决定了,当推理成本高于定价可以覆盖的范围时,厂商面临的压力是一样的。调低默认思考强度,是目前成本和性能之间最容易拨动的那根旋钮。用户感知到的是模型「变笨了」。厂商账面上节省的,是每次调用的边际 token 成本。
Boris Cherny 给出了技术性解法,用户可以通过 /effort high 指令或修改配置文件,手动把思考强度恢复至最高级别。这个解法在技术上可行,但它同时意味着,「最高性能」已经不再是默认设置。
345 美元到 42,121 美元,花掉的不只是预算,还有一个假设:厂商做的默认配置变更,是为了让用户的使用效果更好。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






